DA,可观测的无共识复制
DA 作为异步验证的桥梁,将会是整个 Layer2 系统吞吐的瓶颈。状态更新的速度必须和 DA 的吞吐取得动态平衡,若状态更新速度长期大于 DA, 则肯定会出现由于 DA 无数据导致 Verifier 无法在挑战期内验证状态的情况。于是 DAC 成为了 DA 的一种相对放松的实现成为了不少人的选择:
我们固然希望 DAC 或是别的什么东西既能突破性能桎梏又能完全达到与 Layer2 一致的安全性。有趣的是,我们也明白这等于要求 Layer1 自身突破自身, 于是我们不得不要放松一些 DA 与 Layer1 的联系。最直接的方式是缩小网络规模另起炉灶得到一个 mini Blockchain,当网络足够小时, DAC 若影若现。 但这样的思路是 Layer1 的不可能三角漩涡的涟漪,并没有把 Layer2 作为视角的核心。这也是 DAC 很容易招致本能反感的直接原因, 因为其总是表现为一个依赖信任的伪区块链。
是默然忍受 DA 链跟不上执行的步伐?还是投身于 DAC 的安全黑盒?这两种方案哪一种更高贵?To be or not to be,这是一个问题。
在回答是或不是之前,我们需要回到问题的本源,去审视自己是否提出了一个好的问题。实际上 DA 问题的本源不在于 DA 自身, 而是在于其所处的 Layer2 网络中的位置。
既然从 Layer2 的视角出发,我们先来看看 DA 在 Layer2 标准模型中的作用:
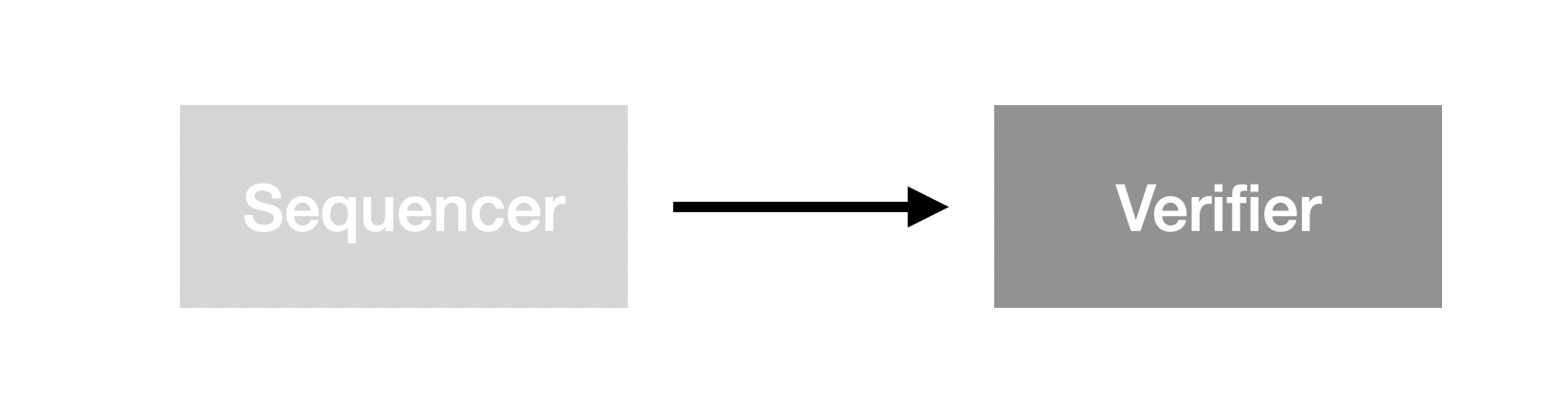
这是一个 Sequencer 与 Verifier 的同步因果关系简图,图中的有向边代表 I/O 因果关系。 Sequencer 的输出直接作为 Verifier 的输入接受 Verifier 的验证。这也链上验证基本模型。 在以扩容为目的 Layer2 网络中,我们无法保证足够强大的即时验证,故而需要 DA 来作为 Sequencer 与 Verifier 之间的异步通信桥梁:

此图可以清晰的反映出关于 DA 的第一个重大设计问题:DA 是否对数据内容有决定权? 换句话说,就是 DA 是否需要共识机制?之所以该问题在这里变得异常突出是因为在讨论 DA 时我们通常忽略了来自 Sequencer 的约束作用, 而把 DA 作为了孤立服务,进而陷入设计上的困境。实际上,在明确指出 Sequencer 作为 DA 的 “因” 之后,关于该问题的讨论才具备完整意义。 我们不难发现,DA 无论如何设计其共识达成的共识也无非是 Sequencer 在 Layer1 的输出,那么 DA 自身的共识就好比在太平洋里倒了一杯水一般微不足道。 自我实现是 Layer1 的招魂术,需要庞大的经济网络支撑其预言自我增强。
令人高兴的是,我们绕开了一层共识负担(DA)。令人难受的是,它基于另一层更重共识网络(L1)来验证数据。又是个“To be or not to be“的问题, 看来我们又提了个现象而非本质问题。
既然我们依赖 L1 校验 DA 的数据,那么我们必须追溯 L1 上的校验数据的来源。由于区块链的调用/空间十分昂贵,通常我们会设置一个缓冲区, 然后以批量的方式往 L1 写入(如果 DA 在 L1 上,等效这种方式):
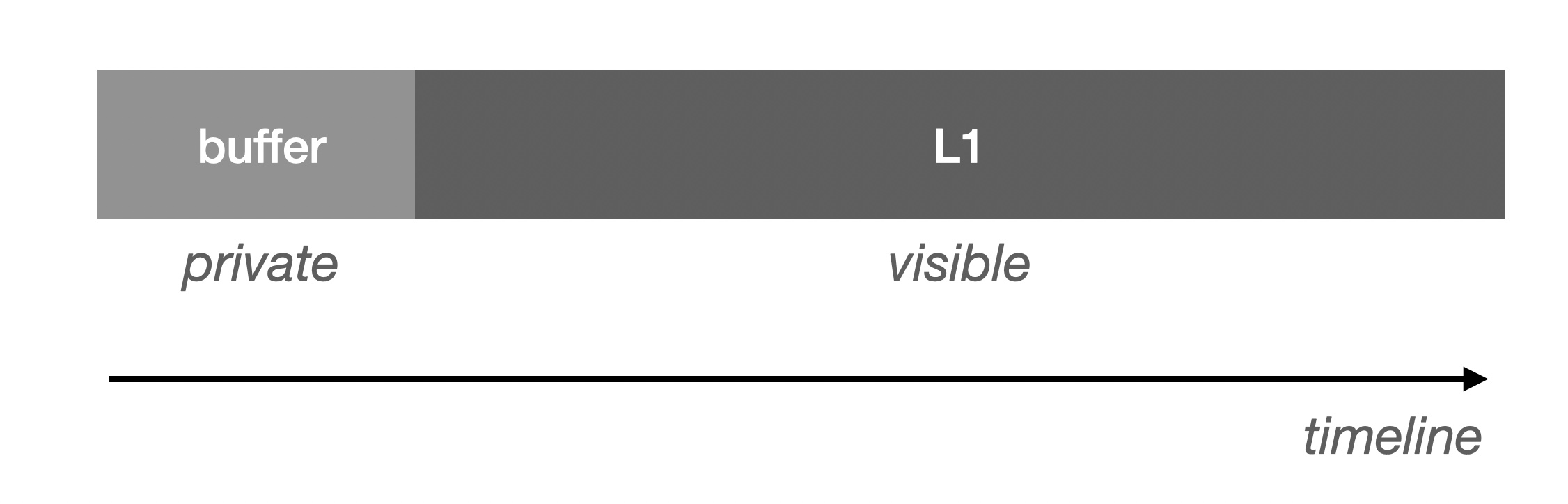
需要说明的是,不可见意味着缺乏因果束缚。对于 Buffer 来说,它通常位于 L2 的 Sequencer 之中,这部分是尚未准备好的数据, 如果直接对外暴露,由于它可能是易变的,Verifier 也没法直接利用它。唯一的确定性时间窗口,是当它准备好刷入 L1 前, 这个时候通过 Buffer 取得数据将可以等待在 L1 写入完成后得到验证。
现在,我们更容易直观理解 DA 限制 L2 的吞吐能力的原因了:
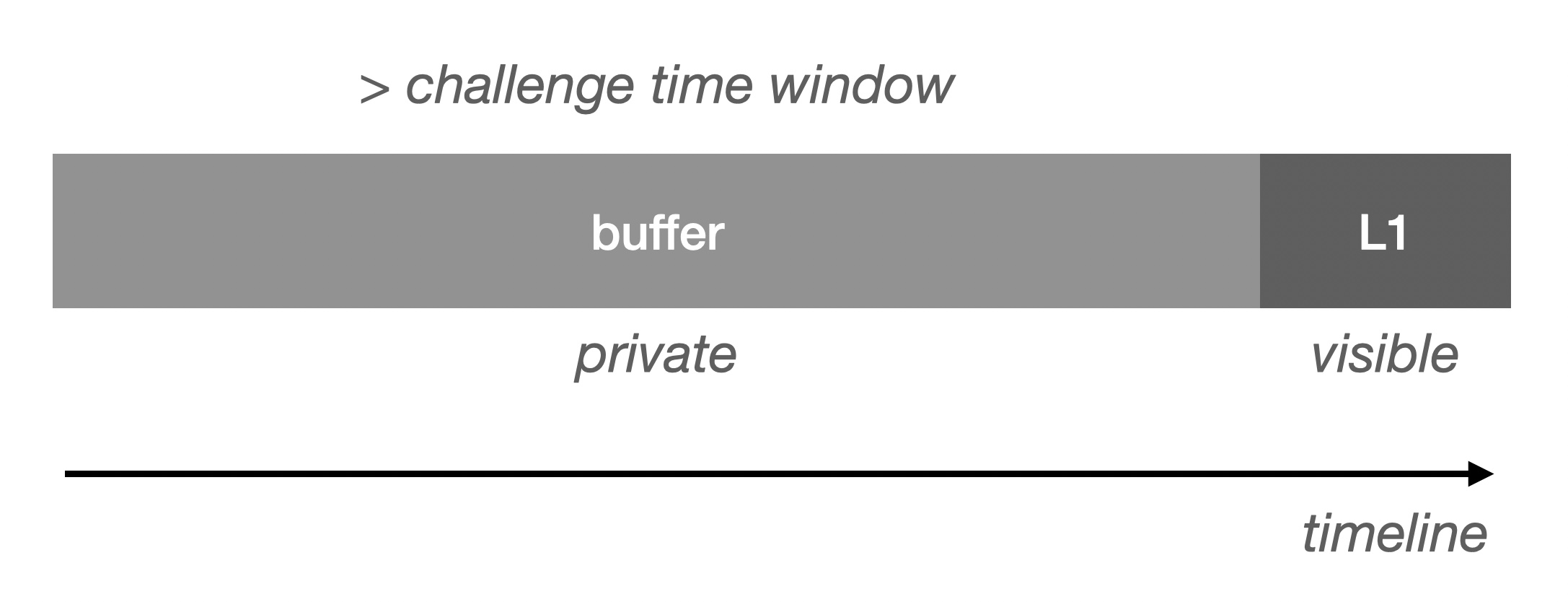
由于 Buffer 和 L1 有速度差,当不限制 Buffer 堆积时势必会出现 Buffer 溢出,这将导致 DA 无法及时写入 L1,从而导致 Verifier 无法按期验证。 为了避免这种情况,我们不得不做限流。
刚才我们提到了 Buffer 的确定性时间窗口(可验证),那么我们可以将这部分暴露出来,如果这部分数据足够大就可以大幅度减少限流的可能性:
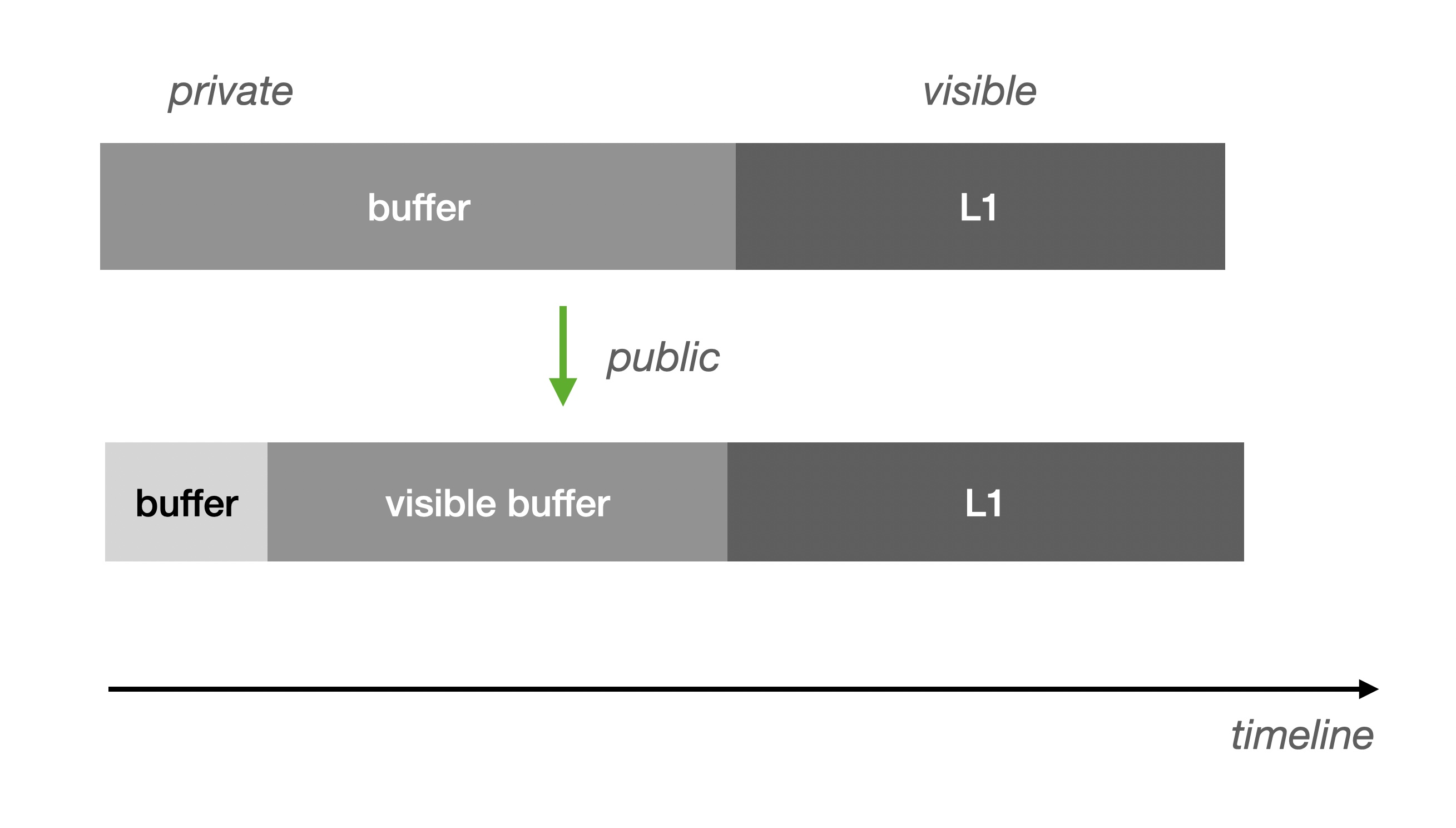
Visible Buffer 与 Data Publication(关于 Data Availability 与 Data Publication 的命名之争后文会再谈一谈)在 Verifier 的支撑作用上是等效的。 不过,这种提高吞吐的方式就不适合将数据发布到 L1 了。另外,还需要压缩数据摘要,我们只需要将一批 Buffer Block 的摘要 root 写入 L1 即可满足验证需求。 否则是毫无效果的,依然会阻塞在 L1 以实现可见性。
目前,我们已知:
- DA 无需共识:依赖 L1 提供数据校验能力
- DA 需要 Buffer:减少 L1 资源占用
- DA 需要 Visible Buffer:提升验证效率
- Visible Buffer 与 L1 Data Publication 等效但不相等的前提是:将数据发布到非 L1 上并压缩验证摘要。否则依然需要等待 L1 阻塞,与 Data Publication 相等。
但功能等效不等于安全性等效。我们固然达不到等同于 L1 的安全假设,但可以尝试做到与 L2 的安全假设等效。 我们希望此安全假设足够简单,能够以一句话阐述上下界,而不是利用人们对确定性的向往兜售复杂而华丽的预言。 易于理解的安全假设能吸引更多的参与者,从而有机会形成安全自我增强。
与 L2 安全假设相对应的,我们的期望:
只需要有一个诚实的 Visible Buffer 节点即可保证安全性。
自然的,我们希望 Visible Buffer 与 Verifier 一样由不同的实体以质押的方式实现去中心化的运行,现在我们给 Visible Buffer 取一个新名字:Data Visibility:
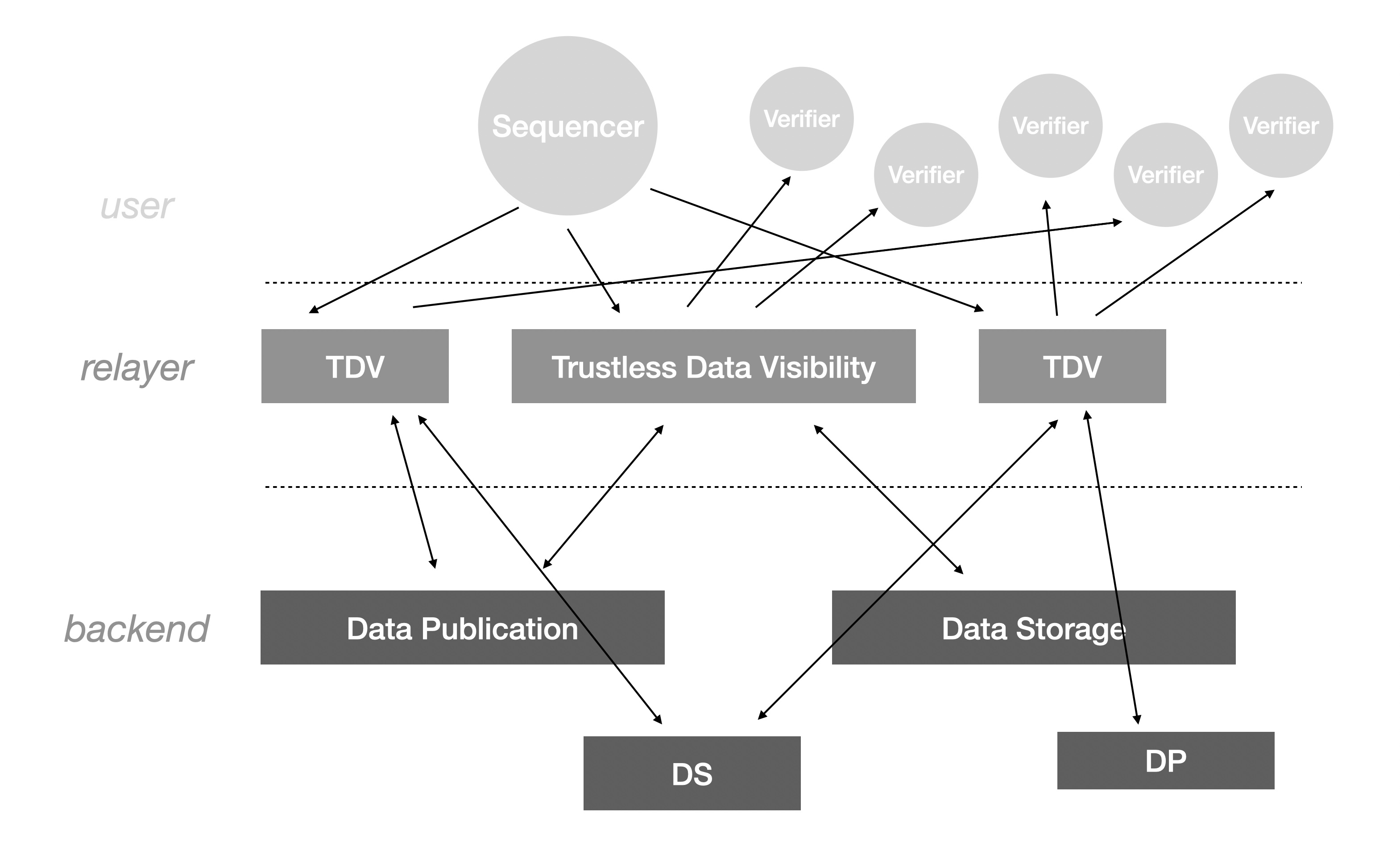
我们将 DA 相关的组件自上而下分为三层:
- user:DA 的使用者,包括 Sequencer 和 Verifier。
- relayer:DA 的去中心化中继节点,由 Data Visibility 构成的 user-facing 服务。
- backend: realyer 所依赖的存储服务,可能是 Data Publication 如果存储对象仅有短期读需求,也可能是 Data Storage 如果存储对象需要长期读需求。具体的实现依赖 relayer 对收益和服务质量的考量。
对于我们来说,现在需要挽起袖子,打足精神,开始详细分析中间层,即 Data Visibility(DV)所面临的具体问题。其作为有状态的存储,必须从 I/O 出发确保其诚实工作:
(1)确保数据被正确写入并保存 (2)确保读取有响应 (3)确保读取响应的完整性
三道铁幕自此徐徐拉开。
第一道铁幕:持久化证明
我们先来看看 DV(Data Visibility) 的第一道铁幕,它等价于如何证明一条水管里流出来的水是来自它自己的蓄水池里的还是从别的地方抽过来的? 水在何处都是 H₂O。这个似乎无解的问题正是 DV 不得不面对一个问题,这是因为在 DV 中每一份数据有公开的多节点可访问冗余, 那么只要有一个持有该份数据的诚实节点,其他节点都可以转发客户端的读取请求。
这个问题最严重的代价并不是不当得利,而是所面临的可靠性风险。这个风险在不同的 DV 数据分布形态中有不同的表现:
(1)基于 Erasure Code 的条带化分布:对于 k+m(k 份原始数据,m份冗余数据)条带,n 个节点,数据均匀分布。至少需要有 kn/(k+m) 个诚实节点才能提供完整数据。 (2)基于完全复制分布:n 个节点各有一份完整数据。至少需要有 1 个诚实节点才能提供完整数据。
让我们回到本小节一开始提到的证明“水是水”的问题。其实水也不是凭空创造的,它也有起因。从水的起因到生成水的结果这一过程我们可以称之为状态(变迁)距离, 比如我们可以很轻而易举的证明我眼前这杯水不是我三秒钟前从喜马拉雅山脉采集的雪水,因为我的速度不足以让我实现这么短的状态距离。基于这一点基本常识,我们可以试图构建证明了:
(1)基本前提:DV 节点收到了准确的数据,并响应了 Sequencer 的写入请求 (2)访问远端存储的状态距离远大于本地存储
对于(1)由于 Sequencer 是 DV 数据的起因,那么 Sequencer 可以持有两份关于数据的摘要,第一份用于端到端校验,第二份作为 DV 上存储数据的 hash。 因为无从预先得知该 hash 值,DV 不得不完全下载全量数据并将计算的 hash 返回给 Sequencer 验证。关于(1)的解决方案多种多样,需要结合具体的 DV 网络架构设计。 需要做到的是避免 DV 不执行实际下载即可。
至于(2)实际上社区也已经做了很多有趣的工作,究其本质都是在尽量减少区块链智能合约开销下的提供基于状态距离的持久化证明:

我们需要 t0 (证明生成时间)与 t1 (本地 I/O 时间)之和小于证明提交期限。为了明显区别于 t2 (远程 I/O),我们这个和尽可能的小于它。 这一点我们可以通过反复大量的随机 I/O 实现,以期望碎片化的请求造成的网络开销显著增长。 状态距离作为强证据(尤其是多轮过后)可以有效识别 DV 节点的不作为, 在未来也可以不断迭代算法和动态调整参数以加强效力。不过需要意识到的是,如果一切检查都要走公链合约执行,其低效必然导致其成为摆设。 因此链下生成证明成为了诸多人的选择,比如利用 Zero-knowledge 很受欢迎。
另外,我们必须明确的是 DV 负责的对象是 Layer2 ,因此在 Layer2 发起的检查是正确的做法(不要忘了,如果 Layer2 作弊将无法通过欺诈证明)。 为了在 Optimistic Rollup 中进一步提升检查效率,我们可以用交互式证明的方式工作:
- Sequencer 按照固定尺寸将数据切成固定数量的切片(不足用0在计算中补齐),并组成 merkle tree。其中 root (下称 object_root) 将等待 DV 返回后验证
- 挑战者生成大量切片 range(如切片1中 [0,256) 字节),并将 range 列表中的数据组成 merkle tree。该列表由挑战者的随机数种子生成
- 挑战者以随机数种子通过 L2 向某个 DV 服务方方发起挑战。若被挑战者满足挑战周期(如七天未被挑战)则挑战发起有效
- 被挑战方根据随机数种子生成 range list,并将在合约规定时间内生成 merkle tree root。否则被惩罚
- 挑战者上传自己的 merkle tree root,如果不匹配。双方通过二分查找找到第一个不匹配的 range hash
- 挑战者与被挑战者均提交该不一致 range 所在的切片,以及切片在 object_root 中的证明
- 合约验证切片存在证明。证明无效则进行相应惩罚
考虑到 DV 服务提供方在初期实现上可能仅是个去中心化的中继节点,实际存储可能完全在远端,而远端存储很有可能不支持 range 请求。 该挑战机制将在初期仅实现切片和摘要算法功能,为以后的升级做准备。另外关于挑战者的激励和安全假设与 OP Rollup 基本相同,这里不再赘述。
第二道铁幕:无响应攻击
无响应攻击是无解的两将军问题在 DV 中的具体体现,DV 节点可以有选择性的响应客户端的请求同时伪装成网络不可达。惩罚这类行为的前提是我们对 DV 节点的可用性有预期, 即我们对 DV 节点的服务可用性有准确要求。
对于 Layer2 来说,即时的大规模的读取需求主要来自于 Verifier 节点,Verifier 作为 Layer2 网络的安全防线自然是可以承担对 DV 可用性检测的责任的, 否则 Layer2 网络不成立。在这个前提下, Verifiers 作为处理两将军问题的相对权威第三方是可以接受的。
因此通过 Verifiers 作用于对抗无响应攻击的最直接方式是:
Verifiers 通过匿藏真实请求地址的方式请求 DV 从而避免 DV 对请求进行识别,并记录 DV 节点的响应质量。将该数据定期作为 tx 定期写入到 Layer2 中以供 DAO 裁决。 DAO 将对 DV 的服务质量进行投票,对不满足条件的节点进行惩罚,对表现优异的节点予以奖励,并实现 DV 服务方轮替。
再此基础之上,我们还可以提供智能合约版本的无响应验证。即发起 Layer2 交易要求无响应节点在一定时间内提供数据。这样的做法的一大问题是脱离了“犯罪现场”, 这与 Verifier 的直接参与有着本质不同。发起请求和搜集请求结果的是同一方才能保证完整的因果关系链条。DV 节点没有理由不响应会带来直接惩罚的链上合约。 这里可以另外延伸出一个话题,即间接证据的重要性。回到智能合约约束上,我们自然还可以利用 Layer1 进行更有权威性的挑战,但由于效率问题几乎难以工作。
简而言之,无响应攻击的探测必须承认第一现场的时空局限性。
第三道铁幕:错误响应攻击
DV 还有第三种关键作弊武器,也是容易被忽视的,因为其背后的问题是如此“沉默”。Silent Data Corruption 实际上无处不在, 但由于其发生的概率较低或是被认为较低,总是得不到有效的保护。在互联网历史上,由于它造成的损失不计其数。那么它对 Web3 世界,尤其是我们现在讨论的 Layer2 网络有多大影响呢?
不同于 Layer1,Layer2 网络缺乏同步验证,静默错误就开始粉墨登场。毕竟,当你自己都不知道自己错误的情况下如何指正自己的错误呢? 而 DV 节点恰好可以利用这一点伪装自己的恶意。它完全可以返回错误响应并表示自己只是很不幸的碰上了静默错误,那么如何区分恶意与无奈? 一棒子打死所有错误响应是十分不妥的,因为静默错误出现的概率远比想象中高!
和处理无响应错误一样,我们需要先建立服务质量预期,在这里主要是网络传输的误码率。解决这个问题的办法很成熟了,也就是无处不在的纠错码。 在纠错范围内,DV 节点的恶意毫无意义,在纠错范围外,我们认为 DV 节点主观作弊了。纠错码的使用代价很低,随时开启它也不会造成吞吐效率的下降。
又如无响应错误一样,这里涉及到事故现场问题。同样的,我们可以引入 Verifier 来提供 DV 节点的原始作弊证据。智能合约的直接判定方式在此不起作用的主要原因也跟上文相同,不再赘述。
Data Visibility 背后的暴力美学
我们知道 DV 是数据存储的巨大缓冲器,它对于突发流量增长的支撑能力决定了 Layer2 网络的上限。与此同时,我们并不总是面临这样的数据洪流, 综合高峰低谷,DV 的服务能力是过剩的。那么,较为慢速的存储是可以充当异步备份功能的。我们的备份甚至可以不局限于地表的大陆, 没有理由不将历史数据沉入海底,或者发射上天,什么能阻止我们这样做呢?
又因为 DV 服务是均质的,任何人可以在尚未加入 DV 网络之前对外提供数据服务,它不需要任何许可,它不需要和其他组建打交道以理解元数据组织并进行复杂的同步过程。 如果它做的更好,DAO 会兴高采烈的迎接它的加入并用它取代表现不佳的 DV。市场竞争对僵化的白名单模式是极具破坏力的,这样的暴力是我期望的。 美德建立在运用暴力的能力之上,如果没有破坏力也就谈不上自我约束,美德也就成了软弱的修辞,高悬的达摩克利斯之剑反射的耀眼寒光令人彬彬有礼。
附录 A: Data Availability, Data Publication, Data Visibility
DA 最近(其实很早就开始了)在概念上进行了进一步明确,从它实际的作用看,它更应该被称为 DP(Data Publication),如此一来它和永久存储的 Data Storage 就明确区分了出来。
在我看来,DA 完全可以作为 DP 和 DS(Data Storage)的抽象层。当我们的存储策略是数据发布时,它表现为 DP,当我们的存储策略是永久存储时,它表现为 DS。 而这篇文章中提到的 Data Visibility 是从 L2 视角发展出的 DA 概念延伸,我们关心的是数据在 L2 上的可见性,至于其后端实现是 DP 还是 DS,我们并不关心。